Après LM Studio, un autre outil revient très souvent quand on parle d’IA locale : Ollama.
Là où LM Studio mise beaucoup sur une interface graphique accessible, Ollama s’adresse davantage aux utilisateurs qui veulent une solution simple, rapide et légère pour lancer des modèles IA depuis leur PC. Il suffit de quelques commandes pour télécharger un modèle, le lancer et discuter avec lui directement depuis Windows.
Ollama permet aussi d’aller plus loin : API locale, intégration avec des applications, automatisation, développement, assistants de code ou interfaces web comme Open WebUI. C’est donc un excellent outil pour passer de la simple découverte à une utilisation plus avancée de l’IA locale.
C’est quoi Ollama ?
Ollama est un outil qui permet d’exécuter des modèles d’intelligence artificielle sur son propre ordinateur. Une fois installé, il peut télécharger des modèles, les lancer localement et les rendre disponibles via le terminal ou une API locale.
Ollama met en avant l’utilisation de modèles ouverts, avec une approche qui peut démarrer localement puis, si besoin, s’étendre vers des modèles cloud plus puissants. Le site officiel indique aussi qu’Ollama peut fonctionner entièrement hors ligne pour certains usages une fois les éléments nécessaires installés.
En clair, Ollama sert à faire tourner une IA sur votre PC sans passer systématiquement par ChatGPT, Claude ou Gemini.
Pourquoi utiliser Ollama plutôt que LM Studio ?
LM Studio est souvent plus rassurant pour débuter, car tout se fait dans une interface graphique. Ollama, lui, est plus direct. On installe, on ouvre le terminal, on tape une commande, et le modèle se lance.
Ollama est particulièrement intéressant si vous voulez :
- tester rapidement plusieurs modèles ;
- utiliser une IA locale depuis le terminal ;
- connecter une IA locale à une application ;
- créer un assistant personnel local ;
- utiliser Open WebUI ou d’autres interfaces ;
- faire du développement avec une API locale ;
- automatiser certaines tâches.
Pour un débutant complet, LM Studio reste souvent plus simple. Pour quelqu’un qui n’a pas peur de taper quelques commandes, Ollama devient très pratique.
Configuration recommandée
Ollama fonctionne sur Windows 10 ou plus récent, selon la page officielle de téléchargement Windows.
Pour une bonne expérience, TechPi recommande :
| Composant | Recommandation |
|---|---|
| Système | Windows 10 ou Windows 11 |
| CPU | Intel Core ou AMD Ryzen récent |
| RAM | 16 Go minimum, 32 Go conseillé |
| GPU | Optionnel, mais recommandé |
| VRAM | 8 Go conseillé pour plus de confort |
| Stockage | SSD avec 50 Go libres ou plus |
| Connexion | Nécessaire pour télécharger les modèles |
Ollama précise que l’installation Windows demande au moins 4 Go d’espace pour les fichiers de base, mais que les modèles téléchargés peuvent ensuite occuper des dizaines, voire des centaines de Go selon ce que vous installez.
Étape 1 — Installer Ollama sur Windows
La méthode la plus simple consiste à télécharger Ollama depuis le site officiel. La page Windows propose un installateur, mais aussi une commande PowerShell :
irm https://ollama.com/install.ps1 | iexPour un débutant, le plus simple reste généralement de cliquer sur Download for Windows, puis de lancer l’installateur.
Une fois installé, Ollama s’ajoute à Windows et peut être utilisé depuis PowerShell, Windows Terminal ou l’invite de commandes.
Étape 2 — Vérifier que Ollama fonctionne
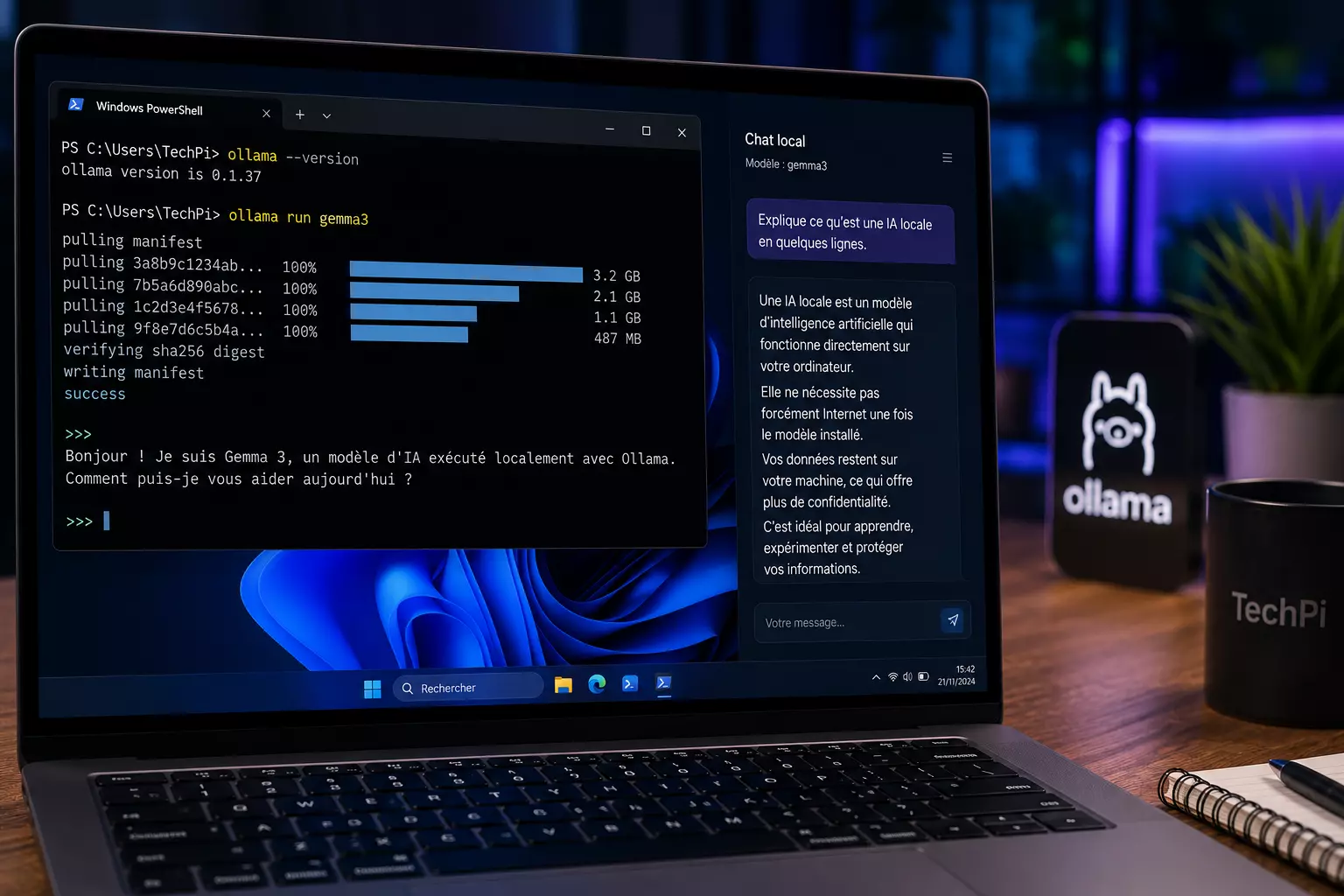
Ouvrez PowerShell ou Windows Terminal, puis tapez :
ollama --versionSi Ollama est bien installé, Windows doit afficher une version ou répondre sans erreur.
Vous pouvez aussi tester directement le lancement d’un modèle avec :
ollama run gemma3La documentation officielle d’Ollama donne justement ollama run gemma3 comme exemple de commande pour lancer un modèle.
Étape 3 — Télécharger et lancer un premier modèle
Avec Ollama, la commande run peut télécharger un modèle s’il n’est pas encore présent sur votre machine, puis le lancer.
Exemple :
ollama run gemma3Au premier lancement, Ollama télécharge le modèle. Cela peut prendre du temps selon la taille du fichier et votre connexion. Ensuite, le modèle se lance et vous pouvez écrire directement vos questions dans le terminal.
Exemple de première question :
Explique ce qu’est une IA locale en 5 lignes, avec des mots simples.Quel modèle choisir pour commencer ?
Le catalogue officiel d’Ollama propose de nombreux modèles, dont Gemma, Phi, Qwen, LLaVA, TinyLlama ou encore des modèles orientés code comme Qwen Coder et CodeLlama.
Pour débuter, évitez les très gros modèles. Choisissez plutôt un modèle compact, plus rapide à télécharger et plus simple à faire tourner.
| Profil | Modèle à tester |
|---|---|
| Découverte | TinyLlama, Phi, Gemma compact |
| Usage général | Gemma, Qwen, Llama selon disponibilité |
| Code | Qwen Coder, CodeLlama |
| Vision / image | LLaVA ou modèle vision compatible |
| PC modeste | Modèle 1B à 4B |
| PC confortable | Modèle 7B à 14B |
Le bon réflexe : commencer petit, vérifier que tout fonctionne, puis tester des modèles plus lourds si votre PC suit.
Étape 4 — Lister les modèles installés
Pour voir les modèles déjà présents sur votre PC :
ollama listCette commande permet de vérifier ce qui est installé localement. C’est utile si vous testez plusieurs modèles et que vous voulez faire le ménage ensuite.
Étape 5 — Supprimer un modèle inutile
Les modèles peuvent prendre beaucoup de place. Si vous n’utilisez plus un modèle, vous pouvez le supprimer avec :
ollama rm nom-du-modeleExemple :
ollama rm gemma3C’est une bonne habitude à prendre, surtout si votre SSD est limité.
Où Ollama stocke-t-il les modèles ?
Par défaut, Ollama stocke ses fichiers dans le dossier utilisateur. La documentation Windows indique notamment que les modèles et la configuration se trouvent dans %HOMEPATH%\.ollama.
Si votre disque principal est presque plein, vous pouvez changer l’emplacement des modèles avec la variable d’environnement OLLAMA_MODELS. Ollama explique qu’il faut créer ou modifier cette variable dans les variables d’environnement de l’utilisateur, puis relancer l’application.
C’est un point important : les modèles IA peuvent rapidement remplir le disque C:.
Étape 6 — Utiliser Ollama via une API locale
Ollama ne sert pas seulement à discuter dans le terminal. Il expose aussi une API locale.
Par défaut, l’API d’Ollama est disponible à cette adresse locale :
http://localhost:11434/apiCette URL est documentée comme l’adresse de base par défaut de l’API Ollama après installation.
Cela permet de connecter Ollama à des scripts, des applications ou des interfaces web.
Exemple de requête simple :
Invoke-WebRequest -method POST `
-Body '{"model":"gemma3", "prompt":"Explique les PC IA simplement.", "stream": false}' `
-uri http://localhost:11434/api/generateOllama fournit d’ailleurs un exemple PowerShell similaire dans sa documentation Windows.
Ollama est-il fait pour les débutants ?
Oui, mais avec une nuance.
Ollama est simple à installer et très rapide à utiliser. En revanche, il demande d’accepter l’idée de taper des commandes. Pour certains utilisateurs, c’est moins naturel que LM Studio.
Si vous aimez les interfaces visuelles, commencez par LM Studio.
Si vous voulez apprendre, automatiser ou connecter une IA locale à d’autres outils, Ollama est un excellent choix.
Ollama et Open WebUI : le duo intéressant
Beaucoup d’utilisateurs associent Ollama à Open WebUI, une interface web locale qui permet d’utiliser les modèles Ollama dans une interface plus proche de ChatGPT.
L’idée est simple :
- Ollama fait tourner les modèles localement.
- Open WebUI fournit une interface de chat plus confortable.
- Vous obtenez une expérience plus visuelle, tout en gardant vos modèles sur votre machine.
Ce sera un bon sujet pour un prochain tutoriel TechPi.
Ollama peut-il utiliser le GPU ?
Oui, selon le matériel et les pilotes disponibles. Ollama dispose d’une page dédiée au support matériel GPU, avec des informations pour NVIDIA, AMD Radeon et Apple Metal. La documentation indique notamment que l’on peut contrôler l’usage de plusieurs GPU NVIDIA avec CUDA_VISIBLE_DEVICES, et liste aussi des GPU AMD compatibles selon les plateformes.
En pratique, pour Windows, les GPU NVIDIA restent souvent le choix le plus simple pour l’IA locale. Les GPU AMD peuvent fonctionner dans certains cas, mais la compatibilité dépend davantage des pilotes et du support logiciel.
Que faire si Ollama est lent ?
Si les réponses sont lentes, ce n’est pas forcément un bug. Le modèle est peut-être trop gros pour votre PC.
Essayez ces solutions :
- Choisir un modèle plus petit.
- Fermer les applications inutiles.
- Vérifier l’espace disque disponible.
- Utiliser un SSD plutôt qu’un disque dur.
- Vérifier que le GPU est bien utilisé.
- Brancher le PC portable au secteur.
- Passer à 32 Go de RAM si vous êtes souvent limité.
La règle est simple : plus le modèle est gros, plus il demande de mémoire, de puissance et parfois de VRAM.
LM Studio ou Ollama : lequel choisir ?
| Critère | LM Studio | Ollama |
|---|---|---|
| Facilité pour débuter | Très bon | Bon |
| Interface graphique | Oui | Plus limité / orienté terminal |
| Terminal | Optionnel | Central |
| API locale | Oui | Oui |
| Automatisation | Bonne | Très bonne |
| Choix pour développeurs | Bon | Excellent |
| Usage grand public | Très accessible | Un peu plus technique |
Pour TechPi, le bon choix est simple :
- LM Studio pour découvrir l’IA locale sans se compliquer la vie ;
- Ollama pour aller plus loin, automatiser et connecter des outils.
Les erreurs à éviter
Installer depuis une source non officielle
Téléchargez Ollama depuis le site officiel. Évitez les installateurs partagés sur des sites tiers.
Télécharger un modèle trop lourd
Commencez par un petit modèle. Un modèle énorme ne sert à rien si votre PC ne peut pas le faire tourner correctement.
Oublier l’espace disque
Les modèles peuvent vite occuper beaucoup de place. Prévoyez un SSD suffisamment grand.
Confondre local et magique
Une IA locale peut fonctionner sans cloud, mais elle n’est pas forcément aussi puissante que les meilleurs modèles en ligne.
Ne pas vérifier les réponses
Comme tous les modèles IA, un modèle lancé avec Ollama peut se tromper, halluciner ou inventer des informations. Il faut toujours vérifier les réponses importantes.
Quelle configuration pour Ollama ?
| Usage | Configuration conseillée |
|---|---|
| Découverte | 16 Go RAM, petit modèle |
| Usage régulier | 32 Go RAM, SSD 1 To |
| Développement | 32 à 64 Go RAM |
| IA locale avancée | 64 Go RAM, GPU avec beaucoup de VRAM |
| PC portable | Bon refroidissement et alimentation secteur |
Pour un usage confortable, TechPi recommande 32 Go de RAM, un SSD spacieux et, si possible, une carte graphique dédiée.
Verdict TechPi
Ollama est l’un des meilleurs outils pour lancer une IA locale sur Windows. Il est léger, rapide à prendre en main et très pratique dès que l’on veut dépasser le simple test.
Il est un peu moins “grand public” que LM Studio, car il repose davantage sur le terminal. Mais c’est aussi ce qui fait sa force : quelques commandes suffisent pour télécharger un modèle, le lancer et l’utiliser dans d’autres applications.
Notre conseil : commencez avec un petit modèle, testez quelques prompts simples, puis connectez Ollama à une interface comme Open WebUI si vous voulez une expérience plus proche de ChatGPT.
FAQ
Oui. La page officielle indique que la version Windows nécessite Windows 10 ou plus récent.
Non, mais il faut accepter d’utiliser quelques commandes dans PowerShell ou Windows Terminal.
Oui, pour les modèles déjà installés localement. Le téléchargement initial des modèles nécessite toutefois une connexion Internet.
LM Studio est plus visuel et plus simple pour débuter. Ollama est plus orienté terminal, automatisation et intégration avec d’autres outils.
Oui. L’API locale d’Ollama est servie par défaut sur http://localhost:11434/api.